Abstract
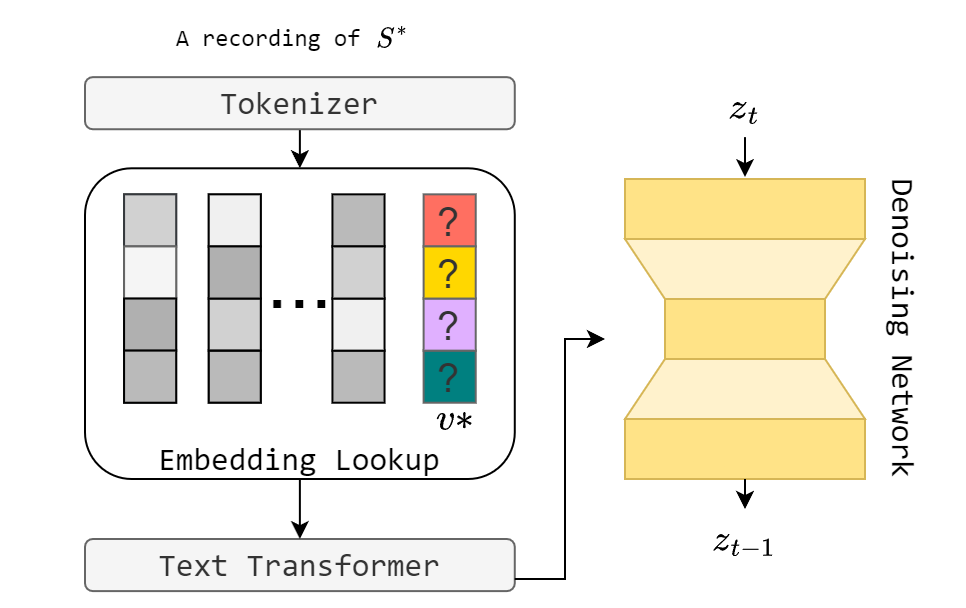
In this work, we investigate the personalization of text-to-music diffusion models in a few-shot setting. Motivated by recent advances in the computer vision domain, we are the first to explore the combination of pre-trained text-to-audio diffusers with two established personalization methods. We experiment with the effect of audio-specific data augmentation on the overall system performance and assess different training strategies. For evaluation, we construct a novel dataset with prompts and music clips. We consider both embedding-based and music-specific metrics for quantitative evaluation, as well as a user study for qualitative evaluation. Our analysis shows that similarity metrics are in accordance with user preferences and that current personalization approaches tend to learn rhythmic music constructs more easily than melody. The code, dataset, and example material of this study are open to the research community.